Paper Presentation from ICCPS '21 [CPS Week]
Papers
Scenario2Vector - Motivation
Safety assessments for automated vehicles need to evolve beyond the existing voluntary self-reporting. There is no comprehensive measuring stick that can compare how far each AV developer is in terms of safety. Our goal in this research is to answer the following question: How can we fairly compare two different AV implementations? In doing so, the aim of this work is to make progress towards an innovative certification method allowing for a fair comparison between AVs by comparing them on similar traffic situations. The goal of our research is to provide a common metric that will facilitate the comparison of different autonomous vehicle algorithms. In order to compare the different AVs, we need to observe them under similar traffic conditions or scenarios. Our goal therefore is to find similar traffic scenarios from the datasets generated by different AVs. Having found similar traffic situations, we can then observe if the output of one AV is more safe/optimal compared to another.
Our Proposal
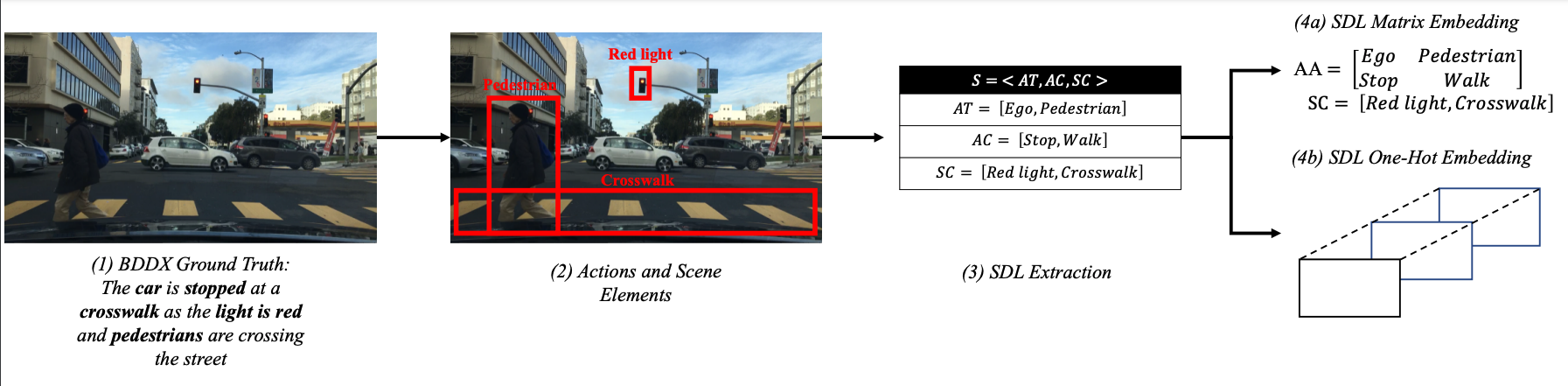
We propose Scenario2Vector - a Scenario Description Language (SDL) based embedding for traffic situations that allows us to automatically search for similar traffic situations from large AV data-sets. Our SDL embedding distills a traffic situation experienced by an AV into its canonical components - actors, actions, and the traffic scene. We can then use this embedding to evaluate similarity of different traffic situations in vector space.
Traffic Scenario Similarity Dataset (TSS)
We present a first of its kind -Traffic Scenario Similarity (TSS) dataset. This dataset contains 100 traffic video samples (scenarios) and for each sample, it contains 6 candidate scenario videos ranked by human participants based on its similarity to the baseline sample.

- About the dataset The Traffic Scenario Similarity Dataset Contains 100 samples. Each sample consists of a baseline video, and six candidate videos. For each candidate video, a human annotator has ranked its similarity to the baseline video to create a ground truth similarity ranking.
- Goal: Our goal was to find a distance metric that would accurately determine the similarity of two input videos. In order to evaluate our distance metrics, we needed a ground truth measure of similarity. However, the BDD-X dataset does not have any measure of similarity between videos. Therefore, we created our own Traffic Scenario Similarity (TSS) Dataset out of the videos in the BDDX dataset.
- Collecting the dataset: In addition to the baseline video and the six candidate videos, the TSS Dataset also includes a list of the ranking of how similar each candidate video is compared to the baseline video. To obtain these ranking lists, we asked participants watch the baseline video and rank the candidate videos from most similar to least similar. When ranking the videos, participants were instructed to pay attention to aspects such as the actions of the vehicles in the video or the presence of road signs.
- Novelty There are many existing datasets for traffic situations, but none that look at comparing video similarity. Our dataset extends the BDD-100k dataset in a previously unexplored direction in this area. You can download the TSS dataset now.v
Acknowledgements
We are grateful to the Commonwealth Cyber Initiative (CCI) for supporthing this research.