Lectures
You can download the handouts for the lectures here.
-
 Lecture 1 - Introduction
Lecture 1 - Introduction
tl;dr: Course Introduciton and Logistics,
[notes]
Suggested Readings:
- Course Syllabus
- Thrun Chapter 1
- Barfoot Chapter 1
- Computing machinery and intelligence, Turing (2009)
-
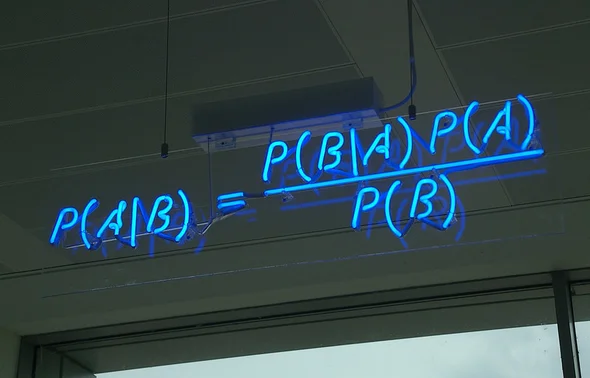 Lecture 2 - Probability Review
Lecture 2 - Probability Review
tl;dr: Review of Probability Theory - 2.1, and 2.2 from Chapter 2 notes
[Chapter 2 notes]
-
-
-
-
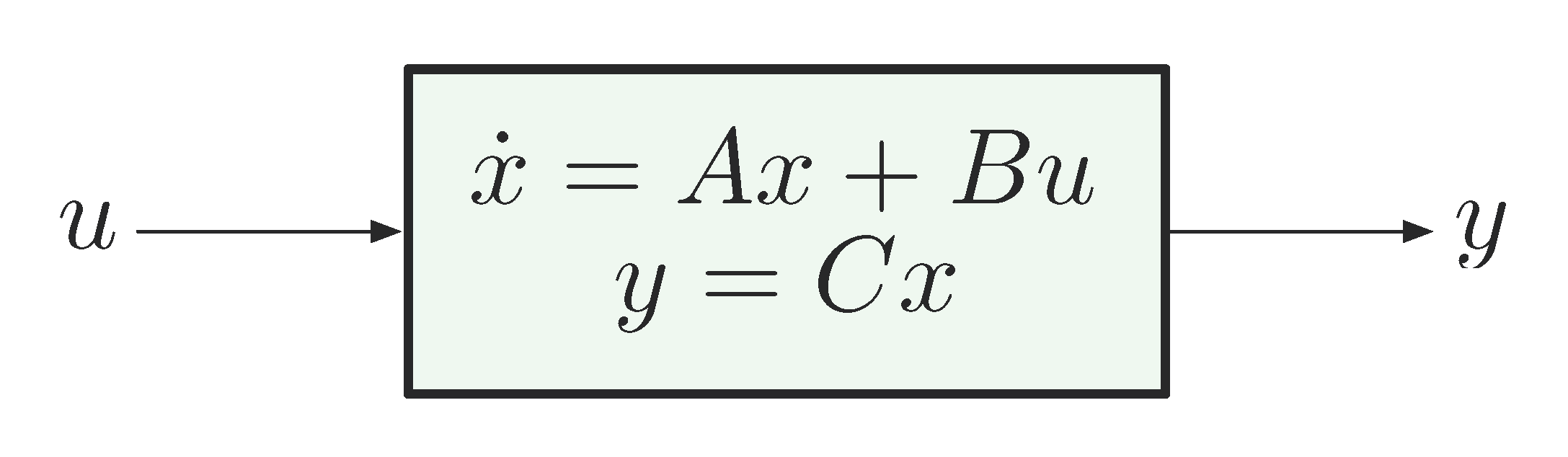 Lecture 7 - Linear State Estimation and Kalman Gain
Lecture 7 - Linear State Estimation and Kalman Gain
tl;dr: 3.2 and 3.3 from notes
[Chapter 3 notes] [Class notes]
-
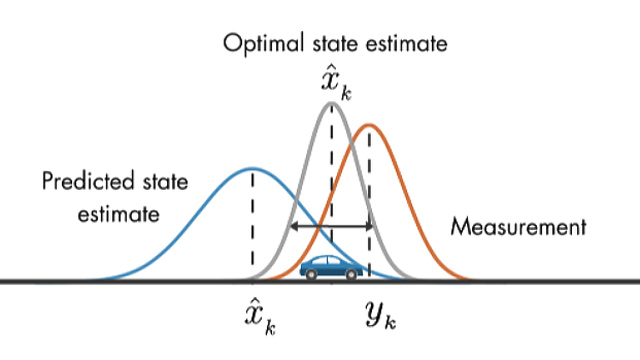 Lecture 8 - Markov Decision Process + Kalman Filter
Lecture 8 - Markov Decision Process + Kalman Filter
tl;dr: 3.4 and 3.5 from notes
[Chapter 3 notes] [Class notes]
-
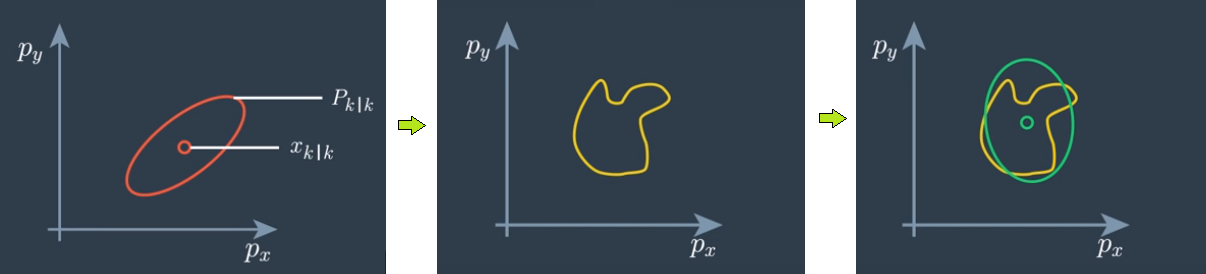
-
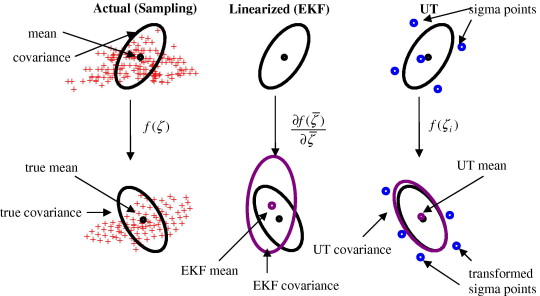 Lecture 10 - Unscented Kalman Filter
Lecture 10 - Unscented Kalman Filter
tl;dr: 3.7 from notes
-
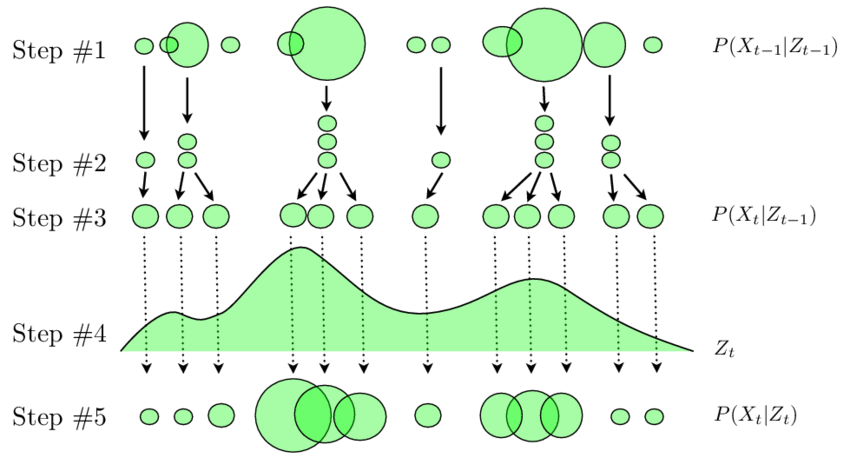
-
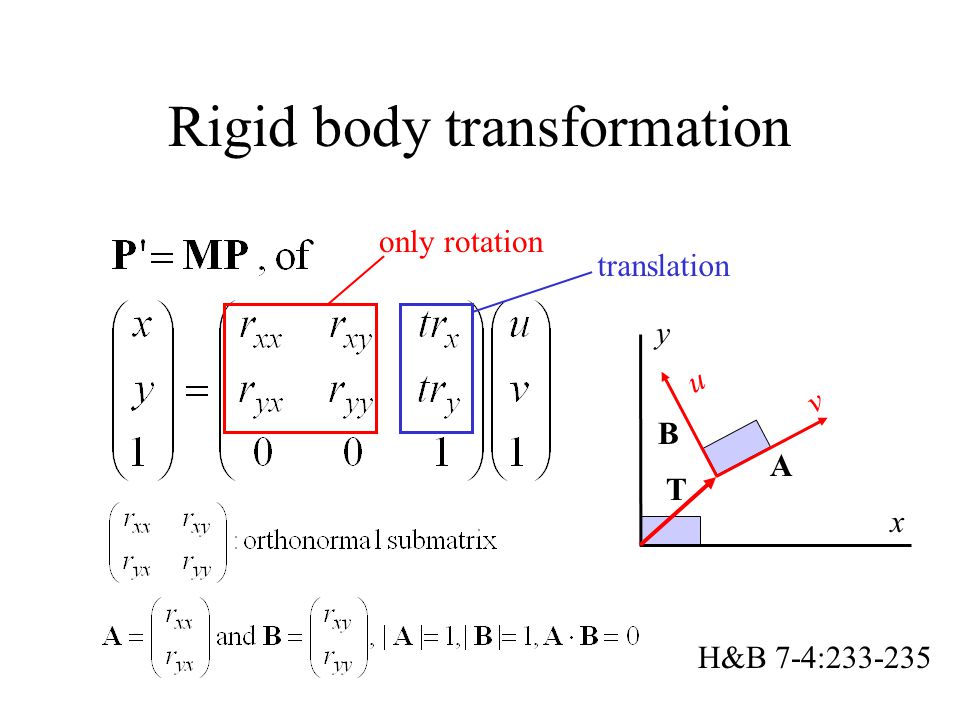 Lecture 12 - Rigid Body Transformations
Lecture 12 - Rigid Body Transformations
tl;dr: 4.1 and 4.2 from notes
[Chapter 4 notes] [Class notes]
-
-
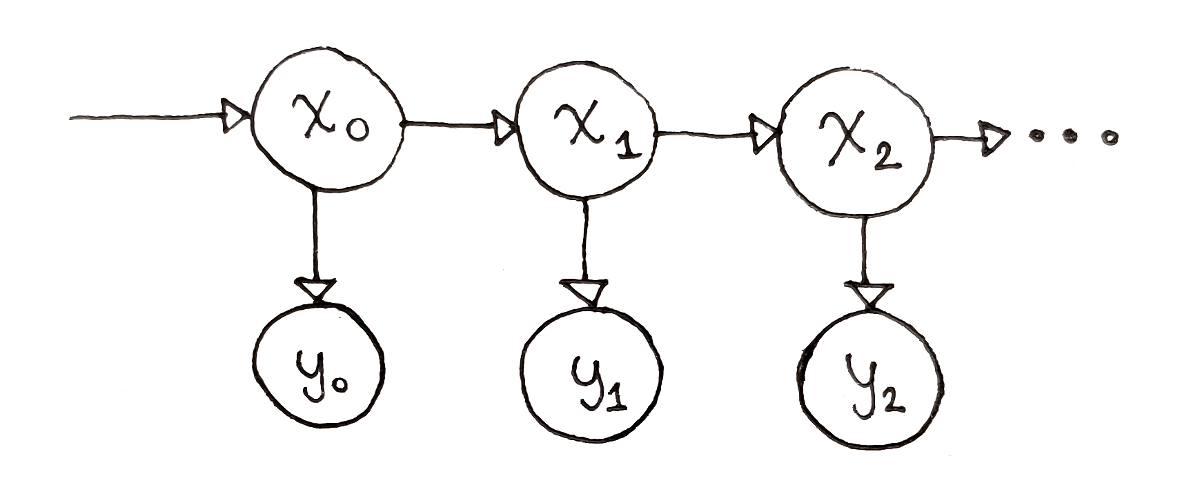
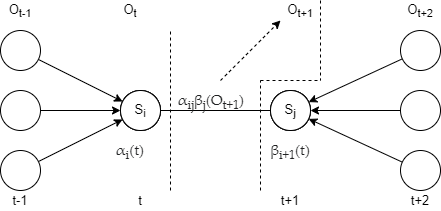
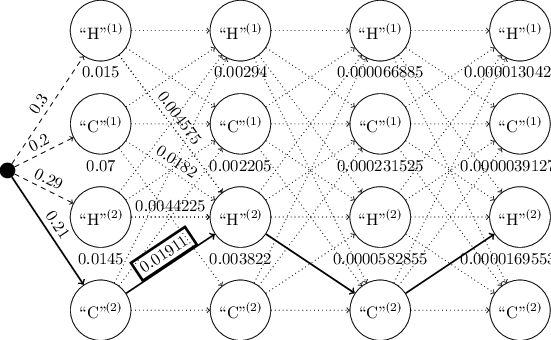 Lecture 5 - Decoding, and Viterbi's Algorithm
Lecture 5 - Decoding, and Viterbi's Algorithm
tl;dr: 2.4 from Chapter 2 notes
[Chapter 2 notes] [Class notes]
-
-
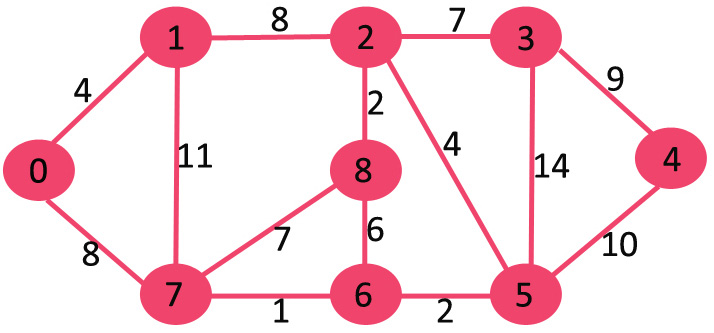
-
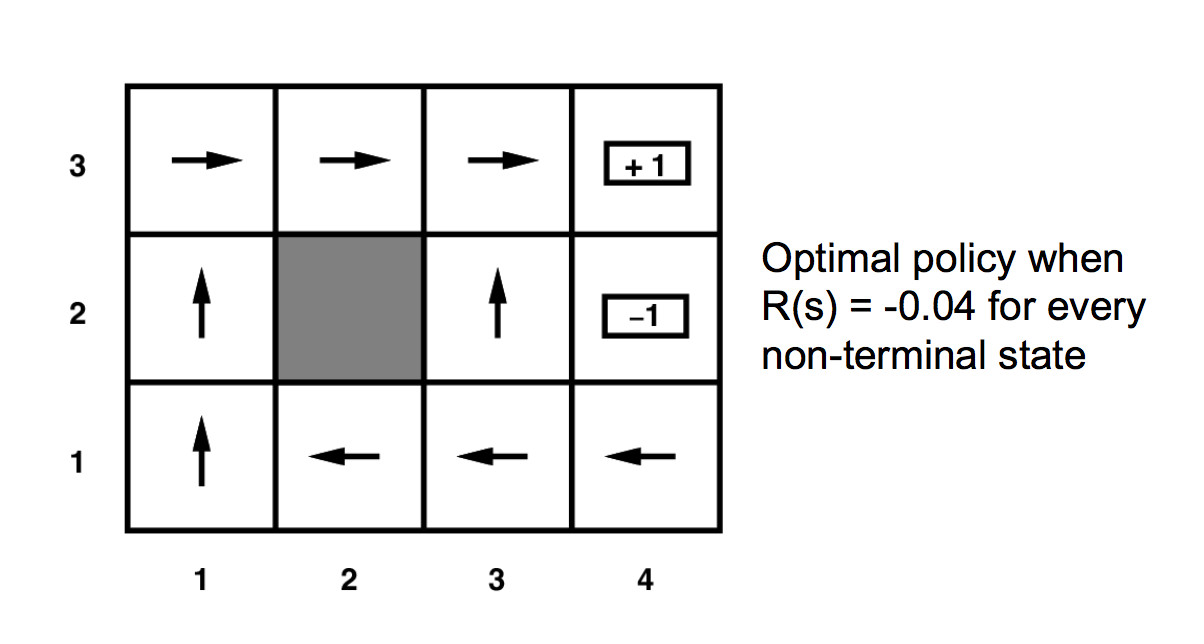
-
 Lecture 17 - Infite Horizon DP, and Bellman Equation
Lecture 17 - Infite Horizon DP, and Bellman Equation
tl;dr: 5.3 and 5.4 from notes
[Chapter 5 notes]
-
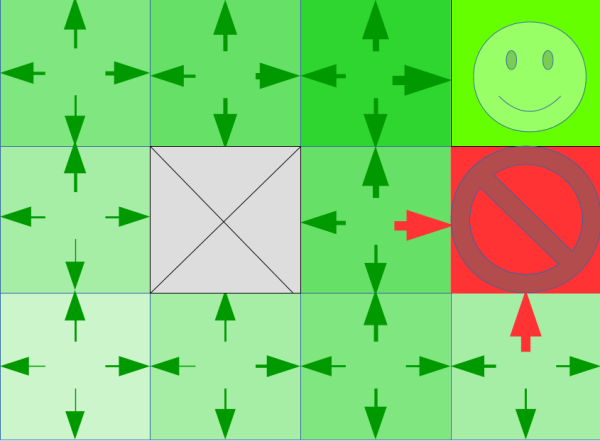
-
-
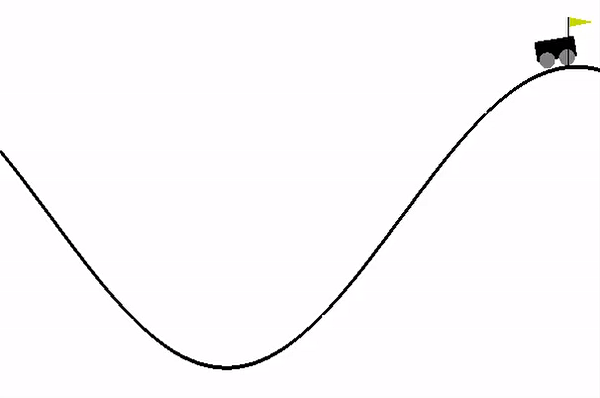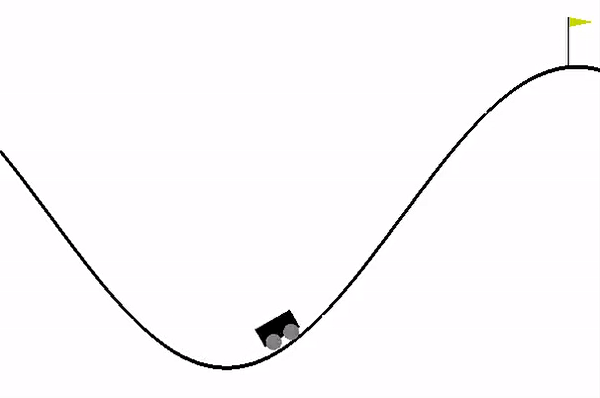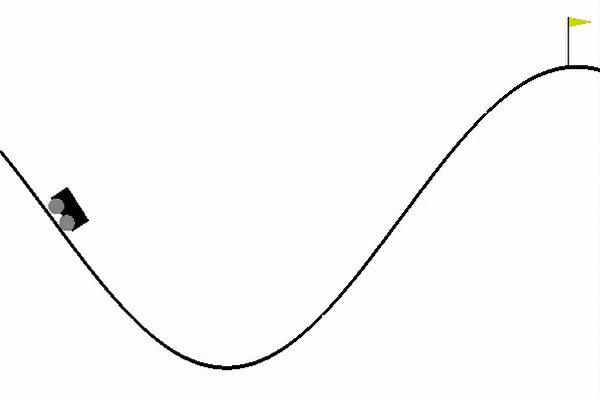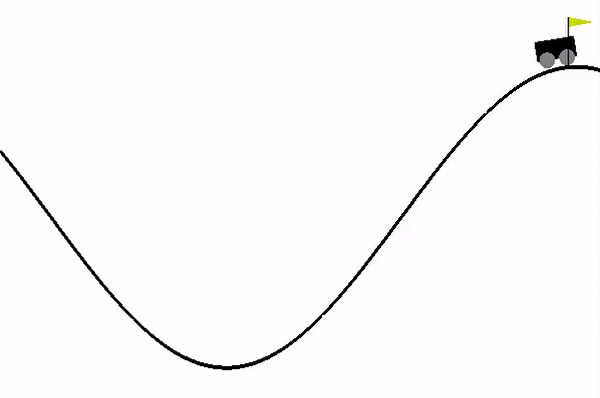
-
-
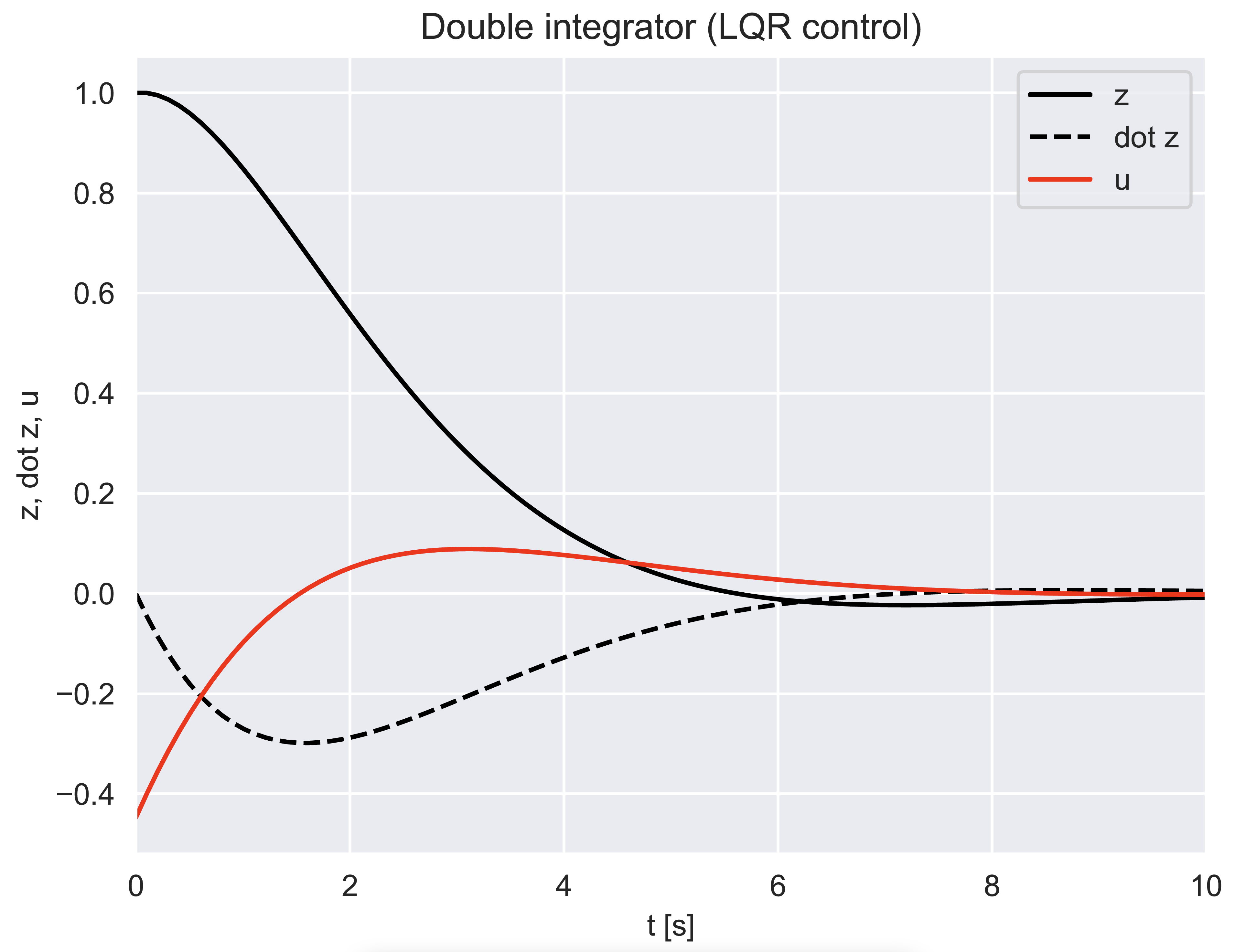 Lecture 22 - Stochastic LQR and Duality of LQR and Kalman Filters
Lecture 22 - Stochastic LQR and Duality of LQR and Kalman Filters
tl;dr: 6.2.2, 6.2.3, and 6.3 from notes + Optional Material from notes
[Chapter 6 notes]
-
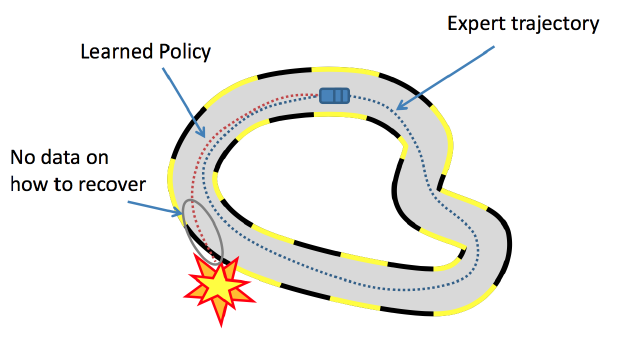 Lecture 23 - Iterative LQR, MPC, and Imitation Learning
Lecture 23 - Iterative LQR, MPC, and Imitation Learning
tl;dr: Chapter 7: 7.1 and 7.2
[Chapter 7 notes]
-
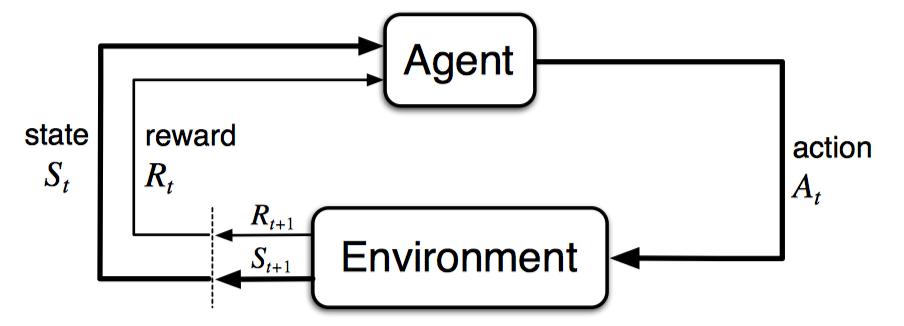 Lecture 24 - BC-Stochastic Control and Chapter 8 - Policy Gradients
Lecture 24 - BC-Stochastic Control and Chapter 8 - Policy Gradients
tl;dr: Chapter 8: 7.3 and Intro to Chapter 8
[Chapter 8 notes]
-
Lecture 25 - Chapter 8 - Cross-Entropy Methods, and Policy Gradients
tl;dr: Chapter 8: 8.1 and 8.2 - Cross Entrompy Methods
[Chapter 8 notes]
-
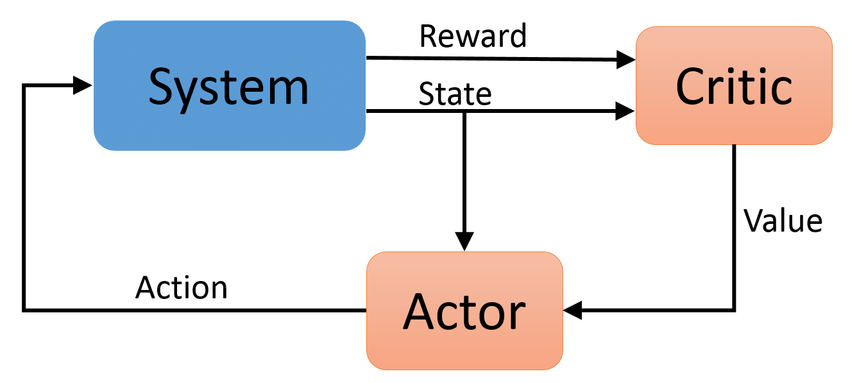 Lecture 26 - The Policy Gradient; Control Variates; Actor-Critic Methods
Lecture 26 - The Policy Gradient; Control Variates; Actor-Critic Methods
tl;dr: Chapter 8: 8.3 and 8.4
[Chapter 8 notes]
-
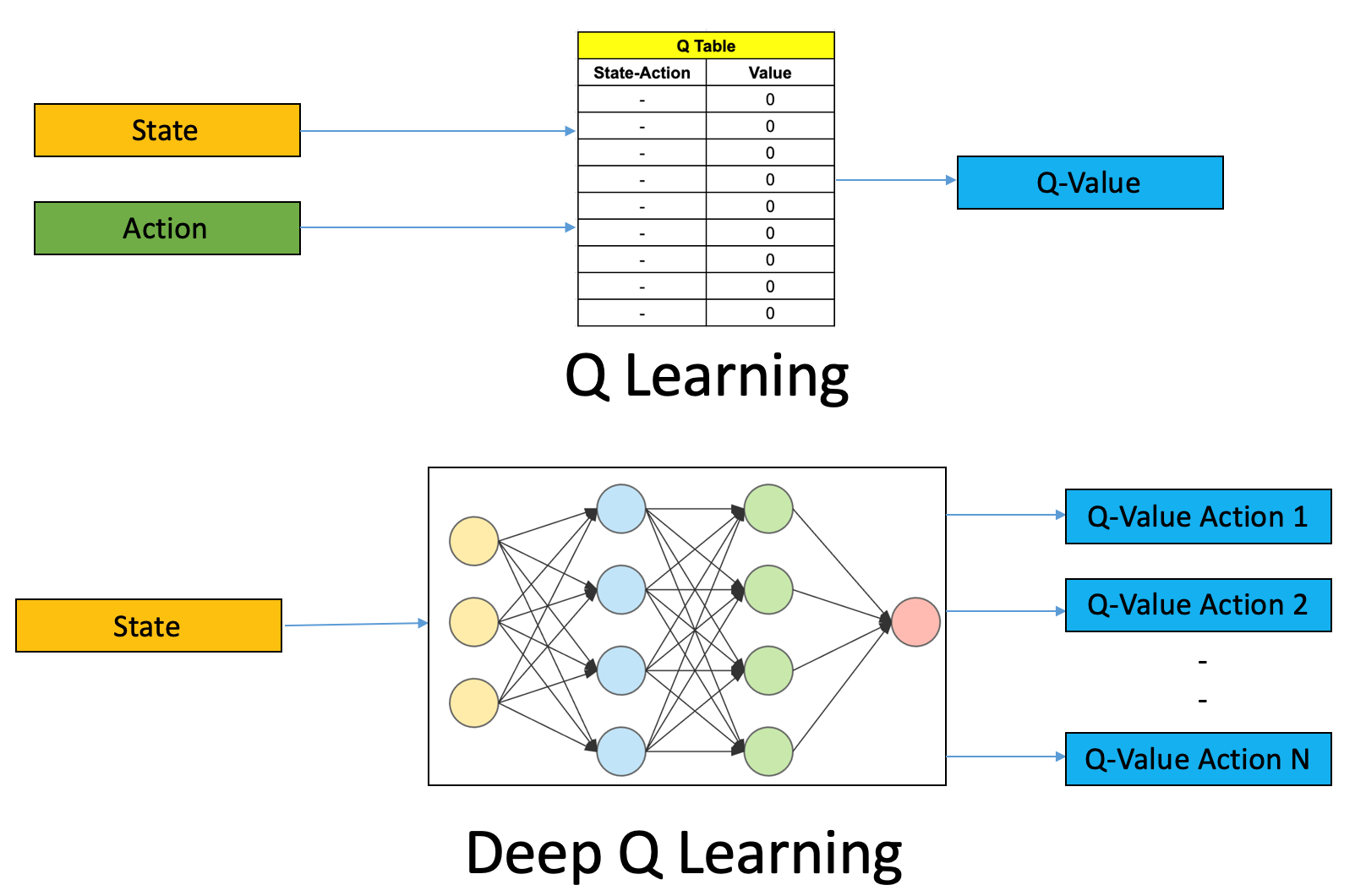 Lecture 27 - Chapter 9 - Q-Learning
Lecture 27 - Chapter 9 - Q-Learning
tl;dr: Chapter 9: 9.1 Tabular Q-Learning and 9.2 - Deep Q Networks
[Chapter 9 notes]
-
Lecture 28 - Chapter 9 - Delayed Targets; Double Q-Learning + Closing remarks
tl;dr: Chapter 9: 9.2.1
[Chapter 9 notes]